

A strange baseball season is bound to produce strange baseball statistics. Through the end of May last season, at which point every team had played 55 to 60 games, only two players had reached the 20-homer threshold, and only one had reached 20 stolen bases. Ten different closers had yet to blow a save (minimum five successful saves). Jake Odorizzi led the American League in ERA.
Imagine the season stopping at that point, with those benchmarks in mind, and the challenge of interpreting any statistical performance or leaderboard in the 60-game 2020 MLB season becomes clear. From the first time baseball fans read the back of a player card, they begin to develop an understanding of the numbers so inherently associated with the sport—but that intuition will be warped this season, the natural mental heuristic unable to activate.

Since many fans first picked up a baseball card, new sorts of numbers have entered the scene, too (if not actually appearing on baseball cards yet). WAR, FIP, DRA, OAA—modern baseball analysis relies on a host of new acronyms that have greatly expanded understanding of the sport and its players. Yet advanced stats aren’t immune from the scourge of small samples either. In such a complicated numerical landscape as a 60-game season, advanced stats might approach their greatest hurdle—but also, counterintuitively, their greatest opportunity to aid understanding above and beyond traditional stats.
The potential difficulty of applying the framework of many advanced statistics to the 2020 season begins with the concept of uncertainty. “What we basically are saying is there’s a difference between what people’s results were in a year and what they actually contributed to those results,” says Baseball Prospectus analyst Jonathan Judge. So if a pitcher allows a run, he is penalized—but whereas a traditional statistic like ERA figures the run was all his fault, wins above replacement understands that his pitching was not the only factor leading to the score. The ballpark also might have played a role, as well as his teammates’ defense, and—depending on the WAR model in question—the umpire and weather and identity of the batter.
Those adjustments make for better, more nuanced analyses of pitcher performance as they manifest in statistics like deserved run average (DRA). Baseball Prospectus’s advanced pitching stat DRA estimates, as the name suggests, the ERA a pitcher deserved after accounting for a whole list of contextual factors. It’s about the most complicated public ERA estimator there is. But it can’t pinpoint a pitcher’s expected result to the hundredth place. There’s some uncertainty baked in.
This is a crucial tenet of sabermetric understanding: Advanced stats do not provide perfect distillations of player value; instead, they offer more realistic estimates than their more traditional counterparts. When BP introduced calculations of uncertainty around pitching stats in 2018, Judge declared it “one of the most important features we have ever introduced at this website.” BP now publishes error bars on advanced stats for pitching, batting, and catcher fielding.
This distinction matters in practice. WAR is the most commonly used advanced statistic now, a catch-all metric designed to summarize a player’s overall contributions in one number. Yet when comparing two different players for the sake of an award race or trade analysis, minor, decimal-place differences in WAR aren’t an automatic signifier that one player is better than the other. In this way, advanced baseball stats operate in a similar manner to political polling: If Candidate A leads Candidate B by 2 percentage points in a poll with a margin of error of 4 points, then there’s a decent chance that Candidate B is actually in the lead.
Here’s a comparative example in baseball terms, from when Josh Donaldson edged out Mike Trout for the AL MVP award in 2015. At one point that September, when Donaldson led Trout by a mere 0.3 WAR, analyst Rob Arthur estimated a 47 percent chance that Trout had actually been more valuable. A lead of a fraction of a win is simply not enough to definitively declare one player’s superiority over the other. (Donaldson would have likely won the MVP anyway, given that he helped Toronto win the AL East for the first time in 22 years, but that’s beside the point here.)
Greater gaps between players means more confident assertions, and vice versa. Was Mike Trout (8.6 fWAR) better than teammate Albert Pujols (negative-0.4) in 2019? Yes, we can say so without any qualms, and any traditional stat could tell us the same. But in the case of super sophomores Ronald Acuña Jr. (5.6) and Juan Soto (4.8)? There’s a lot more uncertainty, and the best we can say is that Acuña was probably a bit more valuable than Soto. In a shortened season, with less time for players of varying skill levels to separate themselves, there will be a lot more Acuña vs. Soto–style comparisons this season, with so many players bunched together on the leaderboards.
In some areas, advanced stats should be able to adjust just fine to an abbreviated schedule. At FanGraphs (which has easily searchable leaderboards by date), last season’s position-player WAR leaders after May were Cody Bellinger and Trout, who both went on to win MVP. The top of the pitching leaderboard was more scattered—Matthew Boyd and German Márquez were in the top five, while Jacob deGrom barely snuck into the top 40—but it still generally cohered with the end-of-season result.
Outside awards races, though, the uncertainty in Trout’s WAR doesn’t matter all that much for the purposes of player evaluation. Whether he was “actually” worth 8.6 fWAR last season, or 7.6 or 9.6 (the margin of error over a full season is typically about one win in either direction), he was still a phenomenal player. But for a 2-WAR player, that margin of error matters a lot more.
That impact should amplify in a shortened season. The greater area of concern for WAR in 2020 appears less at the extremes than the middle of the player pool. Is Decent Player X having a good, merely fine, or actually below-average season? Over the course of 60 games, that distinction won’t be so clear.
While WAR through last May accurately noted the stardom of Bellinger and Trout, most players were stuck in a morass around 0.5 or 1 WAR. It’s difficult to compare players against each other in that range because they’re so tightly packed, and it’s difficult to judge an individual player in that range because the margin of error means he could reasonably be performing at replacement level (0 WAR) or at a near All-Star–caliber rate (1 WAR in a shortened season converting to roughly 3 WAR in a full campaign).
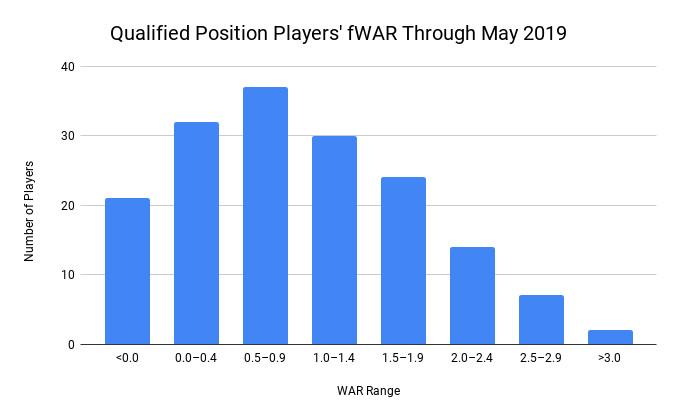
The same appears true on the pitching side. Last season, 238 pitchers threw between 40 and 80 innings, or the amount we might expect from starting pitchers this season. At Baseball Prospectus, those pitchers averaged 0.44 WARP (BP’s version of WAR) with an average margin of error of 0.51 WARP. In other words, the average pitcher with this many innings could have actually been below replacement level (0.44 minus 0.51) or well above (0.44 plus 0.51), and it’s hard to determine which one.
Other contextual factors in 2020 could strain the system even beyond the short schedule. Rules changes like the insertion of a runner on second base in extra innings require tinkering with WAR models, and the regional slate of games could yield extreme park factors, though we won’t know the extent until the games begin.
There’s also the lingering question of the baseball’s behavior. Popular advanced pitching stat FIP (fielding independent pitching), which forms the basis for FanGraphs’ version of pitching WAR, controls for factors like team defense and batted-ball luck. That level of adjustment should help it withstand some amount of small-sample variance. But home runs allowed are a central component of the FIP calculation, so any pitcher who runs into a batch of juiced balls for a start or three could ruin even his advanced statistical profile for the full season.
Yet for as much as the uncertainties of advanced stats will be exacerbated by a shortened season, WAR and its statistical brethren aren’t doomed. After all, they face the same difficulties as traditional stats—and are probably better suited to adjust for this season’s strangeness than their forebears.
“In theory, this is why they exist,” Judge says of advanced stats. “We now have a situation where the ability to think about things like this is going to be incredibly useful.” One bad pitcher outing this season could irrevocably taint his ERA—but if the stat in question acknowledges, like WAR, that those runs allowed aren’t all his fault, the built-in hedges can provide better stability over the otherwise volatile 60 games.
In other words, advanced stats will fare worse in 2020 than they would in a normal season—but traditional stats will, too, and advanced stats should experience less of a drop-off.
For qualified position players last season, 59 percent of the differences in their season-long fWAR totals could be accounted for by differences in their fWAR totals through May. For qualified starting pitchers, that figure was 57 percent. That still leaves plenty of wiggle room—59 and 57 are far from 100 percent—but crossing 50 percent isn’t a bad marker for reliability. And it highlights the distinction between advanced and traditional statistics: In terms of ERA, for instance, qualified starters’ marks through May explained only 32 percent of their final-season figures.
And the more advanced the stat, the better it should theoretically adapt to a shorter season. Judge says that by early June in a normal campaign, BP’s advanced batting and pitching stats are very predictive of where they’ll end up after September. Some individual players might break out or collapse from June onward, but over the whole group, there’s a lot of signal filtering through the noise of the first 60-ish games of a season.
“We’re going to be in a pretty good place to say, you know, if the season would have played out, on balance we’re pretty confident that the person would have turned out awfully similar to where they are now,” Judge says.
The functionality of various advanced stats this season should exist on a spectrum based on the area of play, in addition to the stats’ complexity. Batting is easier to measure than starting pitching, which in turn is easier to measure than relief pitching due to relievers’ even smaller sample.
At the opposite end of batting comes fielding performance, where a standard rule of thumb says three full seasons of data are necessary to accurately peg player performance. When asked about the difficulty of measuring defense in a 60-game season, Judge emits a long sigh, then answers, “Oooh, yeah, that would be hard. … My expectations would unfortunately be pretty low.”
A key problem with evaluating defense is that most batted balls are either routine outs or definite hits. According to Inside Edge tracking data, nearly three-quarters of in-play batted balls last year were gimmes for even the lousiest fielders, turning into outs at least 90 percent of the time. Another large chunk were automatic hits that not even Gold Glovers could reach. It’s hard to demonstrate any sort of separation with those types of plays, and there are only a small percentage in the middle ground where fabulous fielders flash their skills and future designated hitters lag behind.
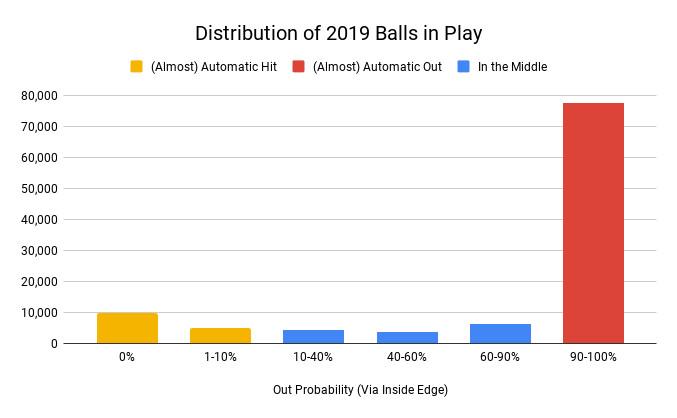
It’s easy to see how this shortage can complicate fielding evaluations. Last season, Oakland shortstop Marcus Semien led the majors in innings played in the field, but according to Inside Edge, he faced only 58 batted balls with between a 10 and 90 percent chance of becoming a hit. Atlanta second baseman Ozzie Albies ranked second in innings; he had 65 such fielding opportunities. Cut the season to a third of its normal length and even full-time fielders will have just 20 to 25 tries to separate themselves as wheat from the chaff.
Like in other areas, small defensive samples can produce real statistical strangeness. Through 56 Dodgers games last season, Bellinger was on pace to shatter the record for most defensive runs saved by a right fielder; he’d already been worth 1.4 defensive WAR by that point, putting him on pace for 4-plus WAR on defense alone over the full season, per Baseball-Reference. Only defenders on the level of Andrelton Simmons and Ozzie Smith have ever reached that high.
That pace seemed unsustainable, and indeed it was, the result of an outrageous stretch of outfield assists that Bellinger couldn’t possibly replicate week after week. He finished the season with 2.0 defensive WAR—still an elite mark (he was sandwiched between Nolan Arenado and Francisco Lindor on the MLB leaderboard), but only halfway to the total his early pace suggested.
The Statcast tracking system might be able to help in smaller samples, with its more granular calculations theoretically allowing for quicker statistical stabilization via its flagship defensive metric, outs above average. Last season, qualified fielders’ OAA values after April could explain 34 percent of their ultimate totals; add in May’s ratings, and that explanatory power rose to an even 50 percent, providing a decent but not great sense of fielder performance.
MLB.com’s Mike Petriello, who works with Statcast data, notes the OAA leaders last April were respected defenders like Simmons, Javy Báez, and Kevin Kiermaier; in May, Byron Buxton topped the list while the likes of Clint Frazier and Vladimir Guerrero Jr. drifted to the bottom. “That to me passes the sniff test pretty well,” Petriello writes via email. “I guess the way I’d approach it is, a month or two isn’t enough to definitively say you know what a particular player’s defensive skill level is, but it’s probably enough to at least get a good idea of who has really stood out or dragged behind.”
OAA still has its liabilities, of course; for outfielders, for instance, it measures only their range, not their arm, and the Statcast system’s new Hawk-Eye technology also must work as intended while being deployed for the first time, with all the complications that come with new technology, amid a pandemic. And it’s still specious in very small samples, which might prove important for a part-time player or someone traded before the August 31 deadline, with only a month’s worth of defensive data at that point.
The defensive picture OAA paints will undoubtedly look blurrier than normal, but crucially, the picture will still be there. Even a fuzzy image is better than nothing—fitting the theme of advanced stats that will measure other areas of performance over a short season.
Perhaps the most illustrative fact about WAR as applied to 2020 is that Baseball-Reference typically doesn’t display WAR at all for the first two weeks of a season, due to the stat’s inherent volatility in such a small sample. But in a 66-day schedule, a two-week blackout means going more than 20 percent of the season without this fundamental metric to examine. According to B-Ref’s Kenny Jackelen, the site will likely act more quickly than two weeks this season to account for the short schedule, but “there will still be some delay beyond opening day before you see the first WAR numbers on the site.”
Yet for analytical purposes, waiting for WAR at least beats trying to tease out the signal from the usual box score stats in a 60-game season, where they will be most influenced by batted-ball luck, quality of opponent, and the rest. Advanced stats are uncertain, but less so than their traditional counterparts. And that mindset fits the 2020 ethos more broadly, anyway. No part about this season is certain. Why would WAR be any different?
